Skinned Multi-Person Linear Model (SMPL)
Realistic 3D model of the human body that is based on skinning and blend shapes

Introduction
In today’s fast-paced digital landscape, the ability to create realistic and adaptable human body representations is essential across a wide range of fields, from animation and virtual reality to video game development. If you’ve ever been curious about the process behind bringing these lifelike 3D characters to life, you’re in the right place. In this blog post, we’ll delve into the innovative Skinned Multi-Person Linear (SMPL) body model—a state-of-the-art method for 3D human body modeling. We’ll explore the technical intricacies of SMPL, guide you through a hands-on demonstration, and discuss its transformative potential in revolutionizing how we engage with digital characters.
Skinned Multi-Person Linear Model (SMPL)
So why do we need these body models?
In animating realistic human bodies, the commercial approach is usually to hand rig the meshes and manually sculpt blend shapes. This approach takes a lot of manual work and hence large amount of time is needed to get the blend shapes right. So the research community has focused on learning a statistical body model from thousands of 3D body scans of real people in different shapes and poses.
Overview of the SMPL Body model
The SMPL body model uses the objective of minimizing the difference between the predicted 3D mesh and the ground truth 3D mesh. To capture how people’s bodies change with different poses, the researchers used 1,786 high-resolution 3D scans of various subjects in a wide range of poses. The model was trained to optimize various parameters, including blend weights, pose-dependent blend shapes, the mean template shape (rest pose), and a regressor that predicts joint locations based on body shape. This joint regressor is crucial for creating realistic pose-dependent deformations for any body shape, as it predicts joint locations as a function of body shape.
The model is trained on a large dataset of 3D scans of different people in various poses. The model is trained to learn the following components:
- Rest pose template
The rest pose template is a 3D mesh of a human body in a neutral pose. It is the base mesh that is used to create the final 3D mesh. - Blend weights
The blend weights are the weights assigned to each vertex of the rest pose template. These weights determine how much influence a nearby joint has on the vertex's movement. - Shape Blend shapes
The shape blend shapes are the deformed versions of the rest pose template that represent a specific shape or expression. - Pose-dependent blend shapes
The pose-dependent blend shapes are the deformed versions of the rest pose template that represent a specific pose. - Joint regressor
The joint regressor is a linear regressor that predicts joint locations as a function of body shape.
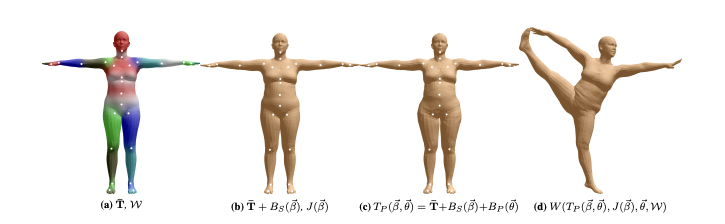
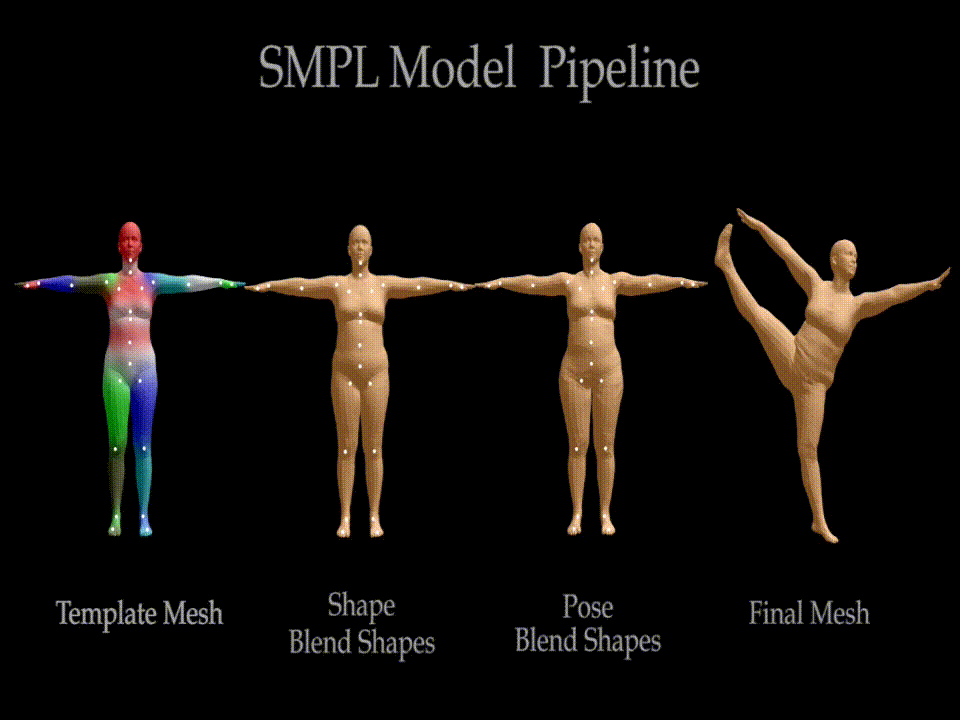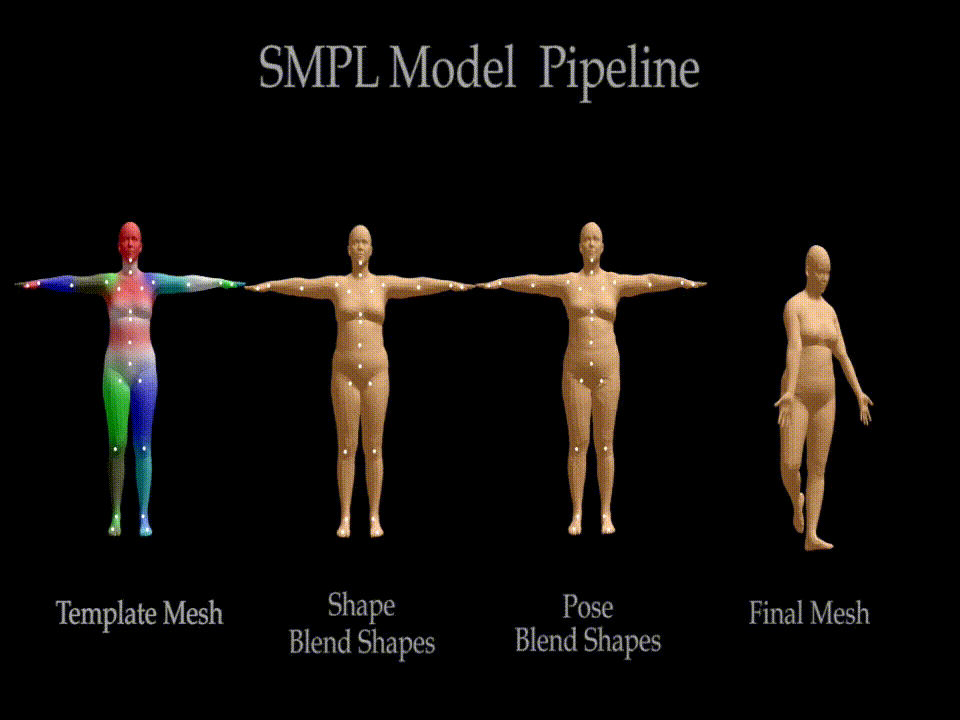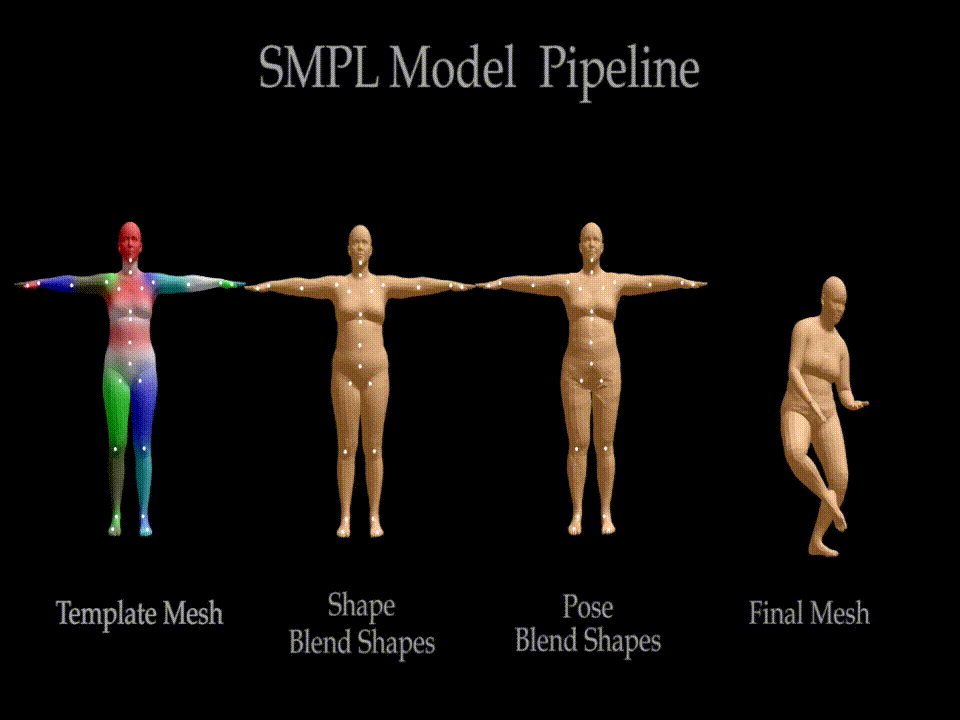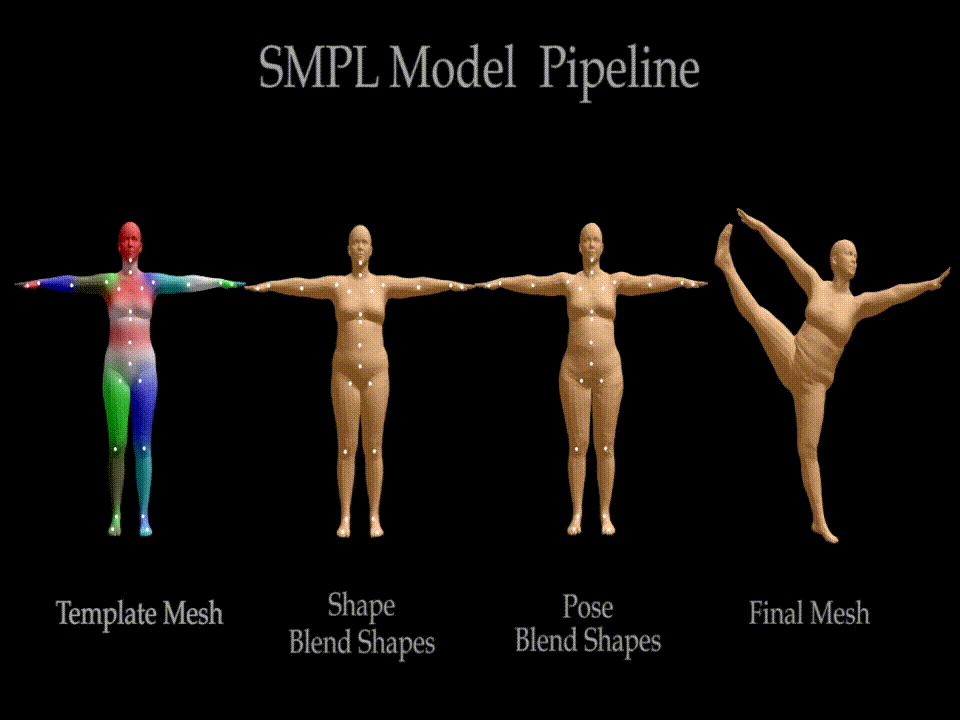
SMPL Model Formulation
The SMPL model is formulated as a linear combination of the rest pose template, shape blend shapes, and pose-dependent blend shapes. The final 3D mesh is obtained by adding the rest pose template and the pose-dependent blend shapes to the shape blend shapes, and then applying blend skinning to the resulting mesh. SMPL takes a vertex-based approach to skinning, which means that the vertices of the rest pose template are transformed by the joints of the skeleton. The weights of the vertices are determined by the distance between the vertices and the joints. The closer the vertices are to the joints, the higher the weight assigned to them. The weights are then used to calculate the final position of the vertices. A single blend shape is represented as created mesh with N=6890 vertices and K = 23 joints.
Following a standard skinning practice, the model is defined by :
- a mean template shape represented by a vector \(N\) concatenated vertices \(\bar{T} \in \mathbb{R}^{3N}\) in the zero pose \(\tilde{\boldsymbol{\theta}}^{*}\)
- \(W \in \mathbb{R}^{N \times K}\) :- a set of Blend Weights (Fig. 2(a))
- \(B_{S}(\tilde{\boldsymbol{\beta}}):\mathbb{R}^{\mid \tilde{\boldsymbol{\beta}}\mid} \rightarrow \mathbb{R}^{3N}\) :- a Blend Shape function that takes as input a vector of shape parameters, \(\tilde{\boldsymbol{\beta}}\), and outputs a blend shape sculpting the subject identity (Fig. 2(b))
- \(J(\tilde{\boldsymbol {\beta}}) : \mathbb{R}^{\mid \tilde{\boldsymbol{\beta}}\mid} \rightarrow w \mathbb{R}^{3K}\) :- a Joint Regressor function to predict \(K\) joint locations (white dots in Fig. 2(b)) as a function of shape parameters, \(\tilde{\boldsymbol{\beta}}\)
- \(B_{P}(\tilde{\boldsymbol{\theta}}) : \mathbb{R}^{\mid \tilde{\boldsymbol{\theta}}\mid } \rightarrow \mathbb{R}^{3N}\):- a Pose-Dependent Blend Shape function that takes as input a vector of pose parameters, \(\tilde{\boldsymbol{\theta}}\), and accounts for the effects of pose-dependent deformations (Fig. 2(c)).
The corrective blend shapes of these functions are added together in the rest pose as illustrated in (Fig. 2(c)). Finally, a standard blend skinning function \(W(\cdot)\) (linear or dual-quaternion) is applied to rotate the vertices around the estimated joint centers with smoothing defined by the blend weights. The result is a model, \(M(\tilde{\boldsymbol{\beta}}, \tilde{\boldsymbol{\theta}}; \boldsymbol{\Phi}) : \mathbb{R}^{\mid \tilde{\boldsymbol{\theta}}\mid \times \mid \tilde{\boldsymbol{\beta}}\mid} \rightarrow \mathbb{R}^{3N}\), that maps shape and pose parameters to vertices (Fig. 2(d)). Here $\boldsymbol{\Phi}$ represents the learned model parameters.$$